No Answer is Better Than Wrong Answer A Reflection Model for Document Level Machine Reading Comprehension
No Answer is Better Than Wrong Answer: A Reflection Model for Document Level Machine Reading Comprehension
论文:https://arxiv.org/abs/2009.12056
会议:EMNLP 2020
任务
自然问题(Natural Questions,NQ)基准集(benchmark set)给机器阅读理解带来了新的挑战:答案不仅具有不同的粒度(长和短),而且具有更丰富的类型(包括无答案、是/否、单跨度和多跨度)。本文通过系统地处理所有答案类型,提出了一种称为反射网(Reflection Net)的新方法,该方法利用两步训练过程来识别无答案和错误答案情况。
谷歌提出的这个新数据集为MRC带来的挑战有两个方面:
- 答案是以两级粒度提供的,即长答案(例如,文档中的一段)和短答案(例如,一段中的一个或多个实体)。该任务要求模型在文档级和文章级搜索答案。
- 在NQ任务中有更丰富的答案类型(包括无答案、是/否、单跨度和多跨度)。
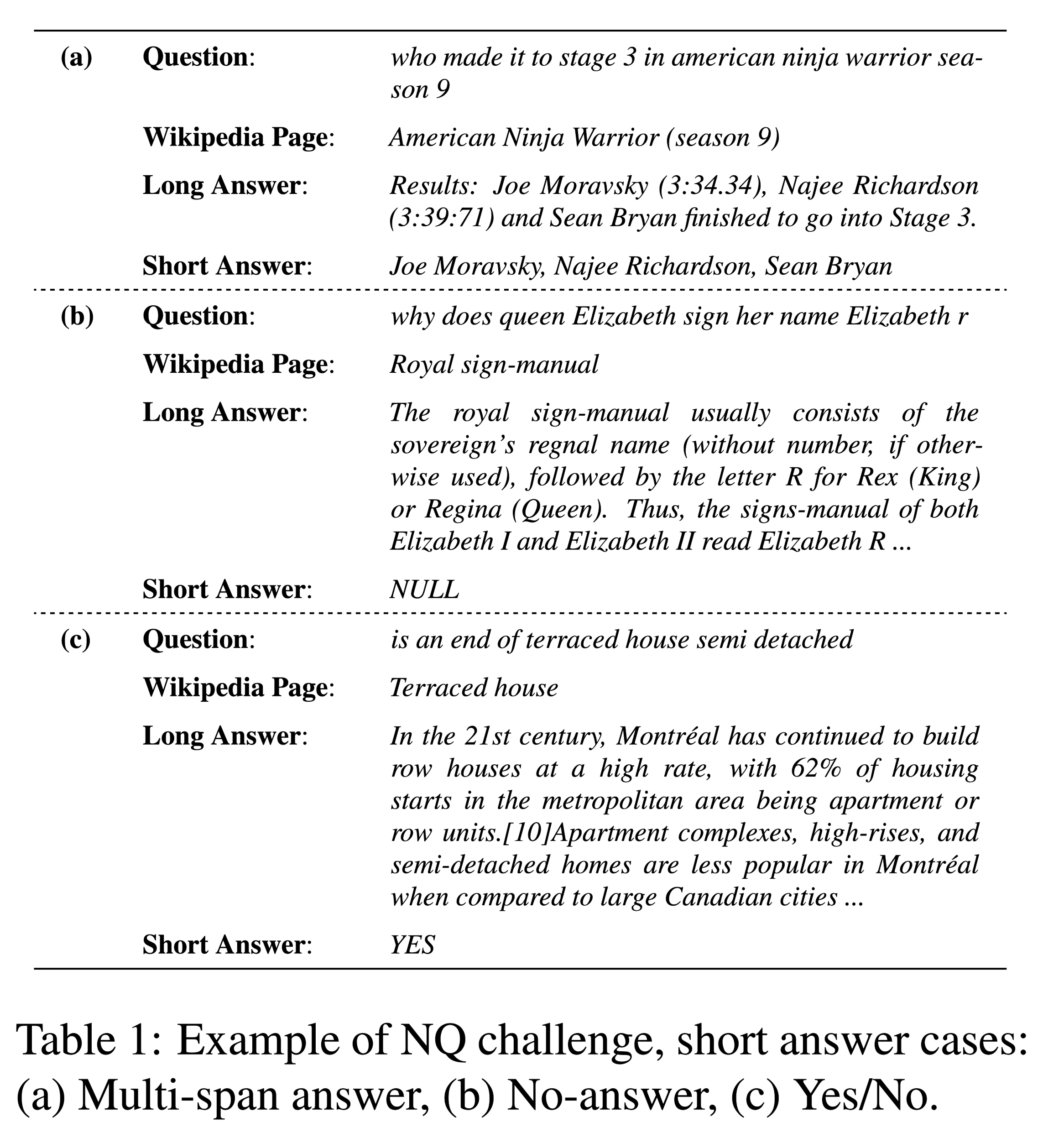
从给的case看,划分答案类型的标准以short_answer为主。
方法(模型)
本文的目标是挑战丰富的答案类型,尤其是没有答案的类型。作者首先训练了一个处理所有类型答案的MRC模型。然后,利用经过训练的MRC模型来推断所有的训练数据,训练第二个模型,称为反射模型,将预测的答案、其上下文和MRC头部特征作为输入,以预测更准确的置信度得分,从而区分正确答案和错误答案。
设计反射模型的原因有三个:
- MRC置信度的计算通常是基于Logit的启发式,它不是标准化的,不同问题之间也不具有很强的可比性。
- 对于长文本来说,负例占的比例太高,会被大量的down sampled,在预测阶段,训练数据和训练数据分布不同,但模型可能会以较高的置信度给出错误答案。
- MRC模型学习问题、类型和答案之间关系的表示,但不知道预测答案的正确性。
模型结构
模型由两部分组成:
- MRC model:预测答案
- Reflection model:计算预测答案的置信度
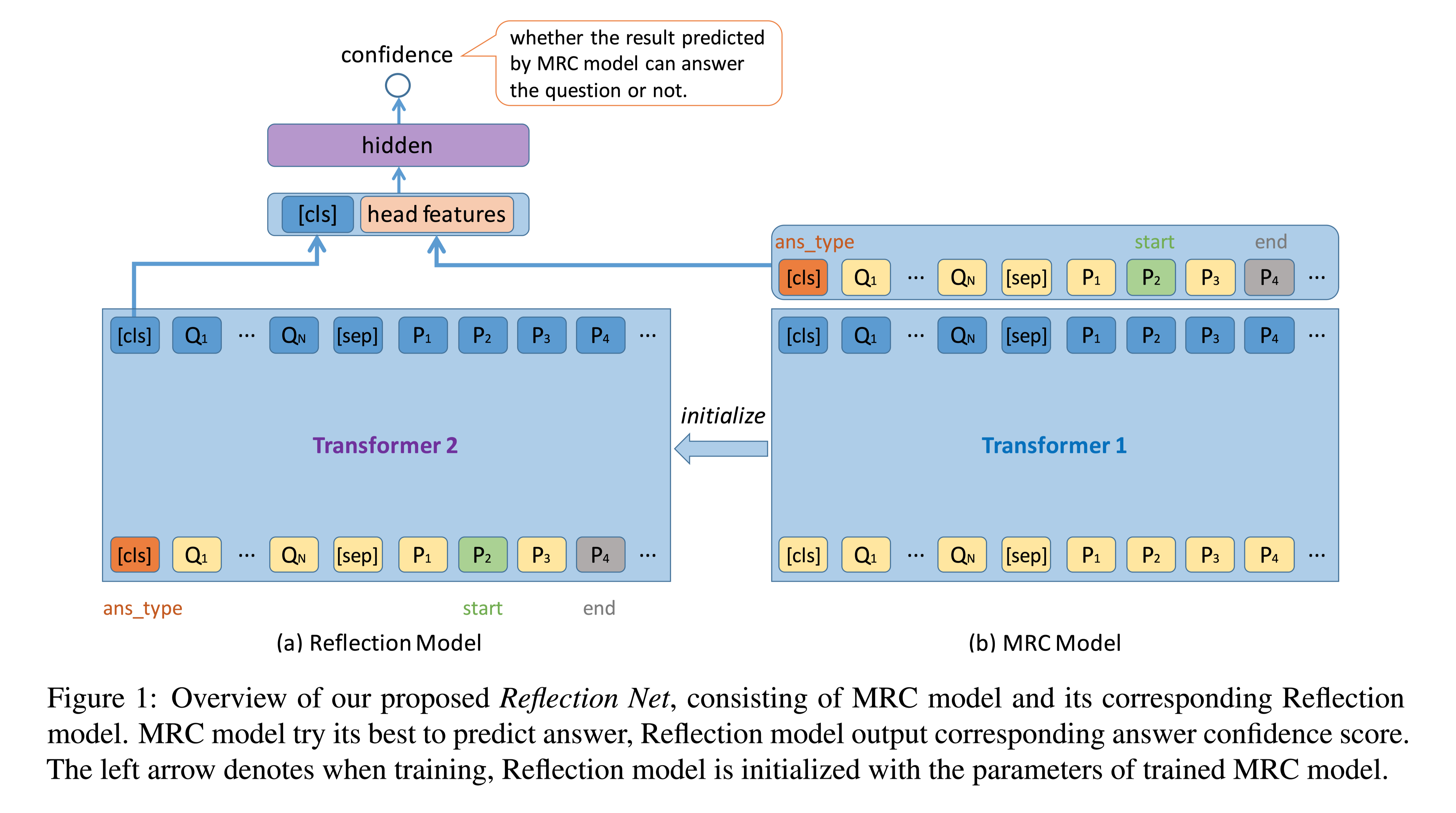
MRC model
MRC model基于pre-trained transformers,使用滑动窗口处理长文本问题,滑动窗口中包含答案的划分为正例,反之为负例。但是对于一个长文本,负例的比例是远远高于正例的,所以本文这块采用了下采样( down-sample )。
输入:
t:答案类型,包括 no-answer的情况
s,e:表示signal-span的开始和结束位置
ms:“:当答案是multi-span时,ms表示答案的序列标签
对于multi-span类型,使用BIO的标注策略(关于BIO之前论文有介绍,检索关键词BIO即可)。
Embedding还是BERT那一套,答案类型的分类通过隐藏层输出的第一个token,[CLS],经过softmax得到各类概率。
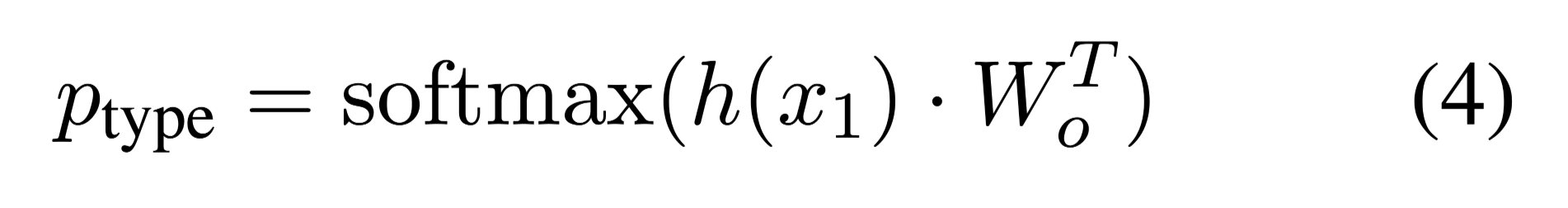
那是如何得到各类概率的呢,$h(x_1)$时$H1$维的张量,$H$事隐藏层维度,$W_o$是$KH$维的,做矩阵乘法之后得到$K$维的输出,$K$就是答案的类别数。
损失函数:
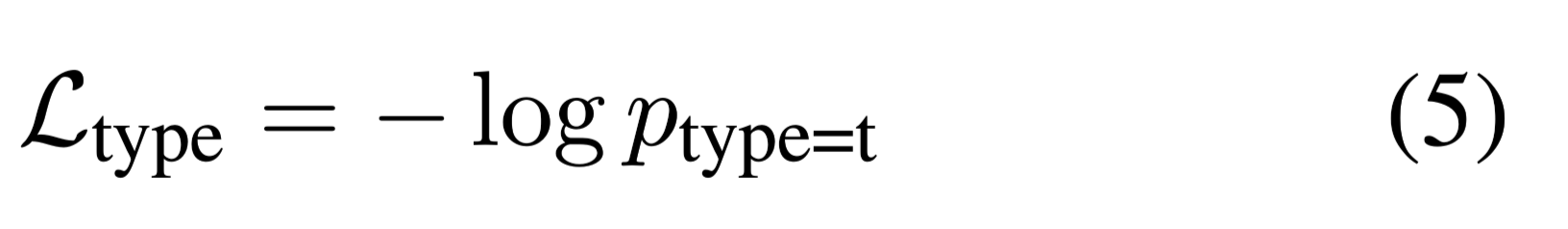
signal-span
对于signal-span只需要预测头尾位置,损失函数为头尾的加和。
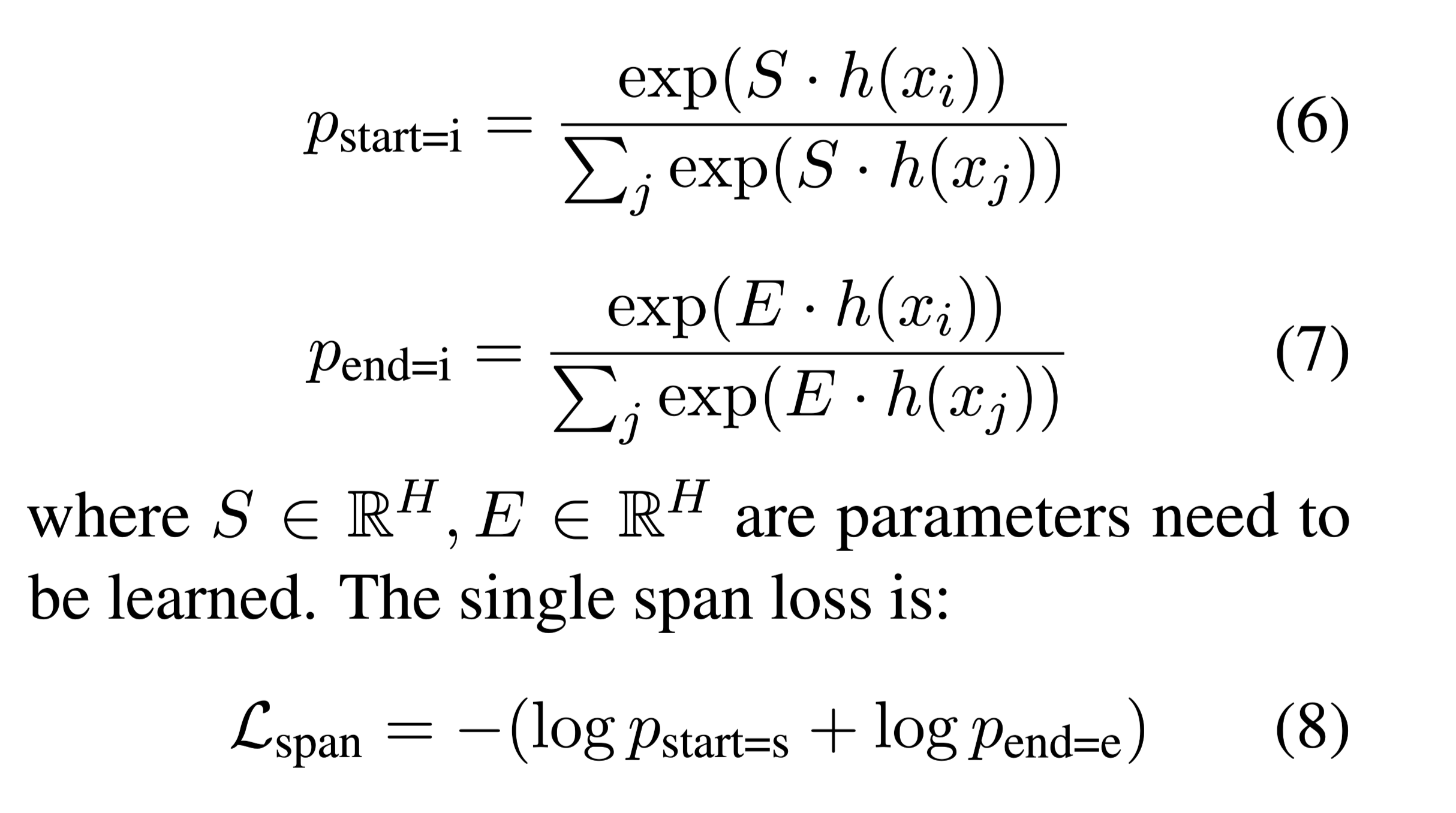
S,E都是可学习参数
Multi Spans
将multi-span类型看作序列标注问题。
为了使损失与答案类型和单跨度的损失相比较,没有使用传统的CRF或其他序列标记损失,而是将每个标记的隐藏层输出表示直接通过线性层,分类为B、I、O标签。
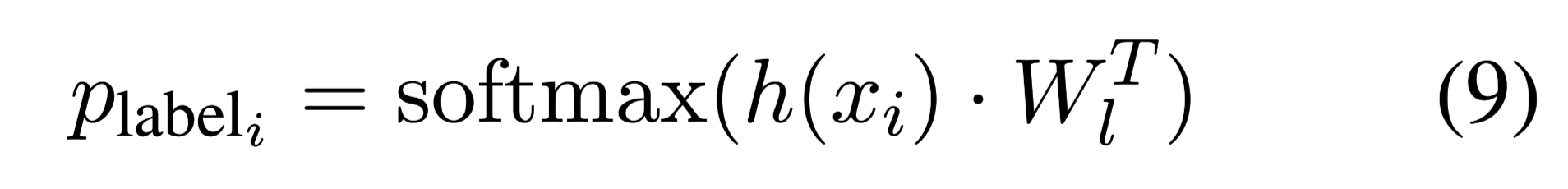
表示每个token标记为B,I,O的概率。
损失函数:
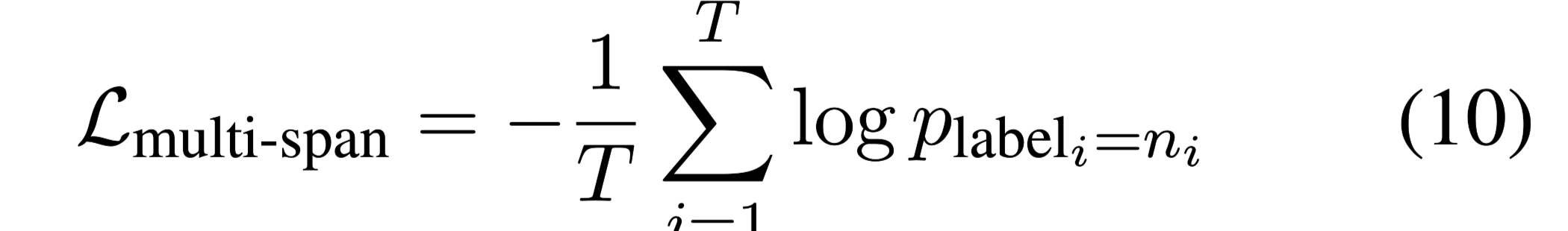
整个MRC model的损失函数:
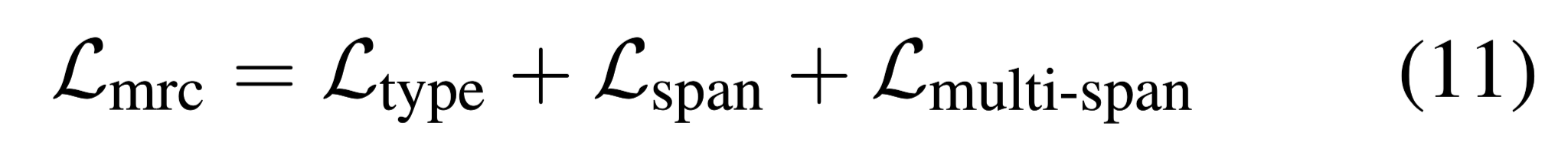
除此之外,MRC model还应该给出每个预测答案的置信度:
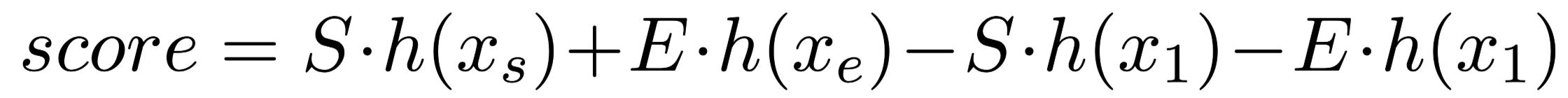
$x_1$表示[cls] tokens。
Reflection Model
反射模型的目标是得到更精确的置信度分数,它可以区分正确答案和两种类型的错误答案。第一个是预测$has-ans$问题的错误答案,第二个是预测$no-ans$问题的答案。
Training Data Generation
让MRC model推理所有的训练数据,选择top-1置信分数的答案作为实例,对于所选实例,MRC model 预测的答案、相应头部特征和正确性标签(如果预测答案与真相答案相同,则标签为1;否则为0)一起作为反射模型的训练样例。
MRC模型必须为每个问题预测一个长文档的所有滑动窗口实例,但反射模型只需要推断一个包含MRC模型预测答案的实例。因此,反射模型的计算量很小。
训练阶段,使用训练好的MRC model作参数初始化。
头部特征一般选 MRC model 的上几层,将[CLS]的隐藏层输出表示与头部特征拼接,用于最终置信度预测。具体头部特征如下:

Embedding:
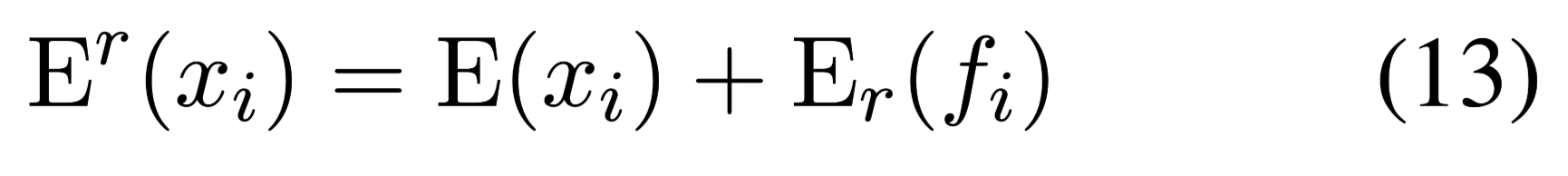
Ans元素:
- 将答案类型标记添加到[cls]标记中
- 将位置标记添加到相应的位置标记中
- 并将空标记添加到其他标记中。
$f_i$是对应于上述token$x_i$的Ans元素之一。
拿到Embedding之后,还是经过Transformer得到隐藏层表示:
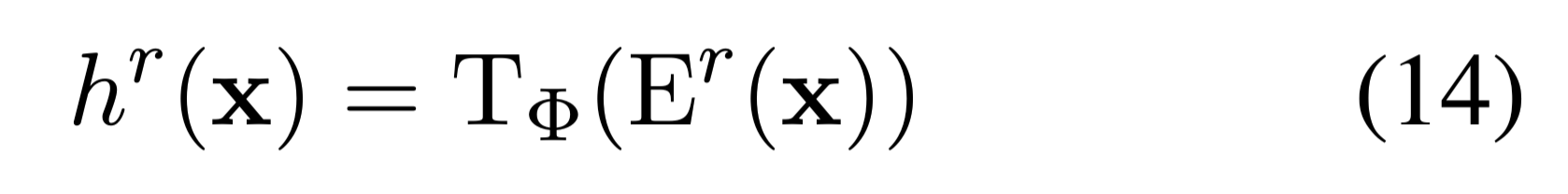
得到隐藏层表示后,将[CLS]和头部特征拼接,输入到线性层:
反射模型将所选实例x和预测答案作为输入。
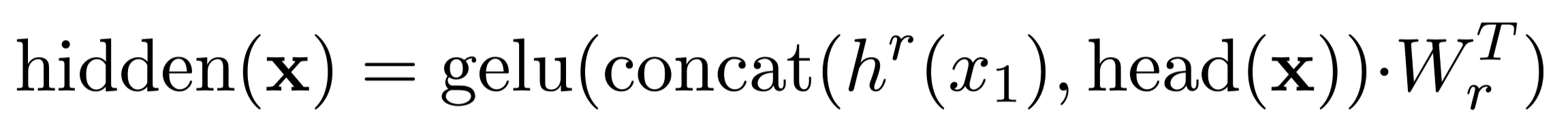
激活函数是GLUE。
置信度$p_r$实际上就是一个概率:

损失函数:
二分类交叉熵损失函数
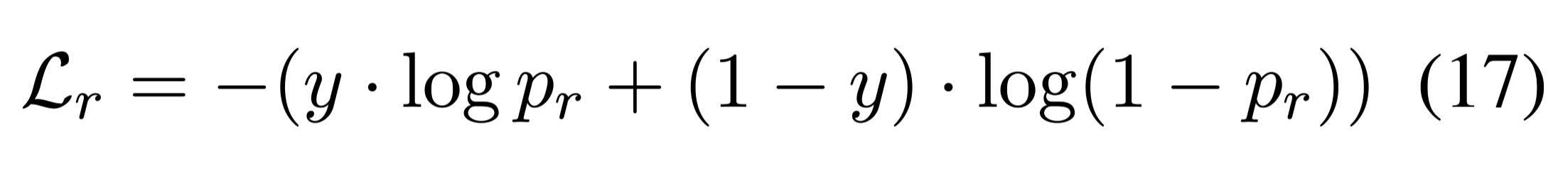
MRC model预测正确时,y = 1。
数据集
Natural Questions (NQ) dataset:
consists of 307,373 training examples, 7,830 development examples and 7,842 blind test examples used for leaderboard
including no-answer (51%), multi-span short answer (3.5%), and yes/no (1%) answer.
性能水平
(R@P=90, R@P=75, R@P=50)表示固定精度下的召回率。
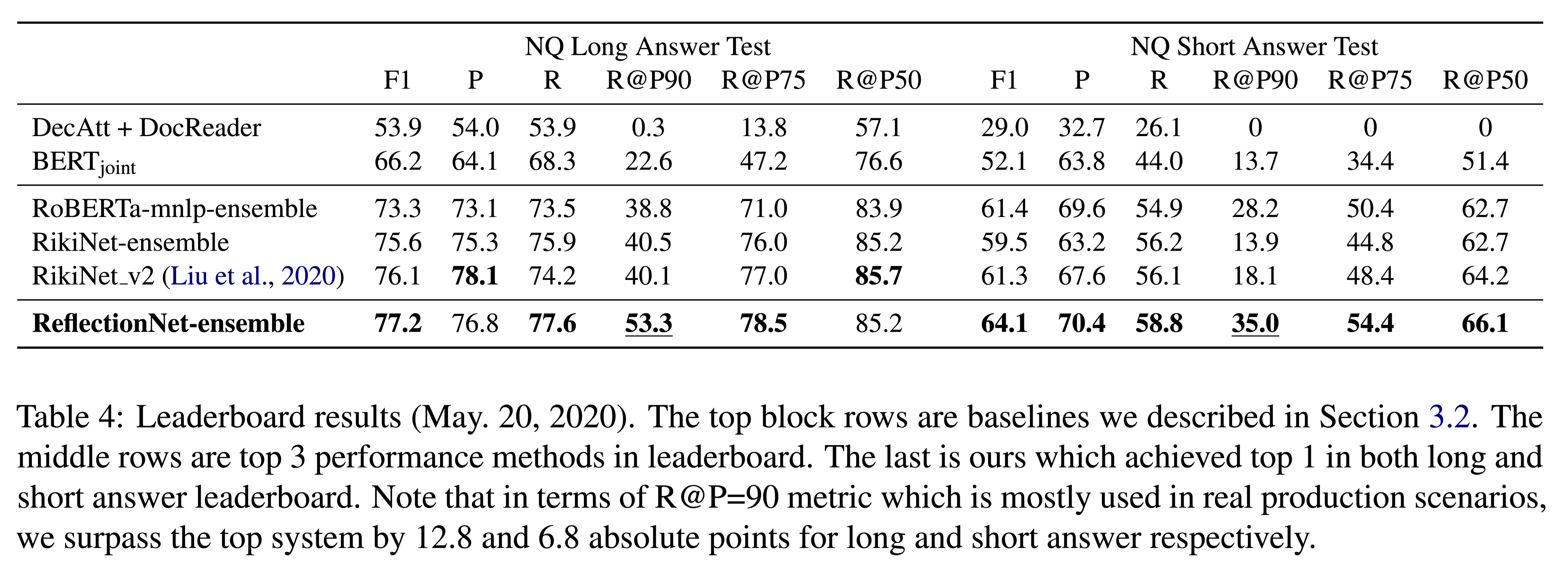
结论
本文是首次在NQ任务中对所有答案类型进行建模。本文提出了一种系统的方法来处理MRC中丰富的答案类型。设计了一个反射模型来解决无答案/错误答案的情况。其关键思想是训练第二阶段模型,并根据其内容、上下文和MRC模型的状态,预测答案的置信度得分。该方法在NQ集上实现了最先进的结果。由F1和R@P=90来看,在长答案和短答案上,本文的方法比以前的顶级系统有很大的优势。